I’m doing some research in continual learning, what is it and what are the latest developments?
Continual Learning: What it is and the latest developments (2024–2025)
Continual learning is an approach to machine learning in which models learn from a stream of data or tasks over time, aiming to acquire new knowledge while retaining previously learned capabilities without retraining from scratch[1][5]. It is increasingly relevant for dynamic, real-world applications such as on-device personalization, robotics, and domains where data distributions shift after deployment[1][3].
This report summarizes core definitions, problem settings, methods, evaluation practices, and practical directions, then highlights notable advances in 2024–2025 in class-incremental learning, online continual learning, and continual adaptation for large foundation models[2][4][16].
Stability–Plasticity Tradeoff in Continual Learning
Conceptual diagrams that illustrate the tension between learning new information (plasticity) and retaining prior knowledge (stability).





What is Continual Learning and Why it Matters
Continual learning (CL) studies algorithms that learn incrementally from a non-stationary stream of data or tasks, which contrasts with conventional training on fixed datasets[1][17]. The core challenge is the stability–plasticity dilemma: the need to acquire new knowledge without erasing previously learned information, a failure mode known as catastrophic forgetting[3][2].
- Task-Incremental Learning (TIL): A task identifier is provided at inference to disambiguate which task the model should solve, often allowing task-specific components or heads[3][5].
- Domain-Incremental Learning (DIL): The task remains the same while the data distribution shifts across time or domains, requiring adaptation to new contexts[3][5].
- Class-Incremental Learning (CIL): The number of categories grows over time without a task ID at test time, often considered the most challenging setting due to open-set discrimination across old and new classes[3][2].
CL is useful in practice because it can reduce full retraining costs, support personalization and on-device updates under privacy or resource constraints, and enable targeted model editing without rebuilding entire pipelines[1][5].
Core Methodologies
Most CL methods can be grouped into three families: replay-based, regularization-based, and architecture-based approaches[3][5][1].
| Approach | Key idea | Typical tools/examples | Pros | Cons |
|---|---|---|---|---|
| Replay-based | Interleave a small buffer of past samples or synthetic data during training on new data | Rehearsal buffers; generative replay | Strong empirical retention | May breach privacy or storage limits |
| Regularization-based | Penalize changes to parameters important for past tasks | Elastic penalties, knowledge distillation | Simple to apply, no raw replay | Weaker in complex shifts |
| Architecture-based | Allocate new capacity or modules while freezing important parts | Adapters, dynamic subnetworks | Parameter isolation protects old skills | Model growth and routing complexity |
Replay is often the strongest baseline but depends on storing or synthesizing prior data, while regularization avoids raw data storage at some cost to performance in harder regimes, and architectural strategies protect old skills by isolating parameters for new tasks[3][5].
Online Continual Learning (OCL): Real-time Adaptation
Online continual learning emphasizes one-pass, real-time data streams and immediate adaptation, which is particularly relevant to robotics, autonomous systems, and speech processing[16]. OCL typically processes non-revisitable data, may face disjoint label spaces across time, and performs single-epoch updates per segment of the stream[16].
Key challenges include catastrophic forgetting under tight compute and memory budgets, and the unreliability of commonly used online accuracy metrics which can be gamed by spurious label correlations[16][19]. A near-future accuracy metric has been proposed to better evaluate rapid adaptation without being misled by stream-local correlations[19].
- Model-centric OCL mirrors the three families: replay-based rehearsal or generative replay, weight regularization and distillation, and capacity-expanding architectures[16][17].
- System-centric OCL shifts learning to orchestration at inference time without gradient updates, using a teacher–student loop and persistent memory to guide future actions adaptively[18].
Benchmarks span image classification, detection and segmentation, multimodal vision-language tasks, and activity recognition, reflecting the breadth of real-world streams studied by OCL[16].
Continual Learning for Foundation Models and LLMs
As large foundation models face model staleness after expensive pretraining, continual learning provides mechanisms to update knowledge, personalize behavior, and maintain alignment without full retrains[2][4].
- Continual Pretraining (CPT): Incrementally refresh general knowledge to handle distribution shifts and add domains or languages without starting from scratch[4][2].
- Continual Fine-tuning or Instruction Tuning: Sequentially add skills or instructions, often using PEFT such as LoRA or adapters to update a small subset of parameters while protecting core abilities[4].
- Continual Alignment: Update value alignment as preferences and norms evolve, maintaining helpful and safe behavior over time[2].
- Compositional and Orchestrated Systems: Combine specialized models or agents and update their coordination for higher-frequency adaptation and better scalability[4].
Latest Developments (2024–2025)
Class-incremental learning (CIL) in 2024 featured several advances to reduce forgetting without storing old exemplars, and to prepare feature spaces for future classes[15][8].
- Prospective Representation Learning (PRL, NeurIPS 2024) compresses base class embeddings and reserves feature space for future classes, then places new prototypes to minimize interference, showing gains on CIFAR-100 and TinyImageNet[8].
- Future-Proofing CIL (FPCIL) uses text-to-image diffusion to synthesize images of future classes, strengthening the feature extractor during the first incremental step and outperforming alternatives that use related real images[14].
- Multi-Teacher Distillation (CVPR 2024) creates diverse teachers through mechanisms like weight permutation and feature perturbation, delivering significant gains with teachers occupying different low-loss regions and orthogonal embeddings[13].
- Federated CIL with LANDER (CVPR 2024) leverages label text embeddings as anchors to guide data-free knowledge transfer and improve sample synthesis and retention under privacy constraints[10].
- Meta-learning for real-world CIL (Scientific Reports 2024) introduces a transformer-based aggregation function and surrogate novel classes for training, reducing the need for retraining when new classes arrive[12].
- First-principles re-examination of CIL reframes problem assumptions and comparison protocols, encouraging fairer accounting of model storage and memory budgets[11][9].
In 2025, reporting indicates rapid growth in CL research for LLMs, with expanded multimodal work, efficiency gains for replay variants, and exploration of hybrid routing and sparse adapters as potential production paths, though full production-grade continual updates in flagship models remain limited so far[6].
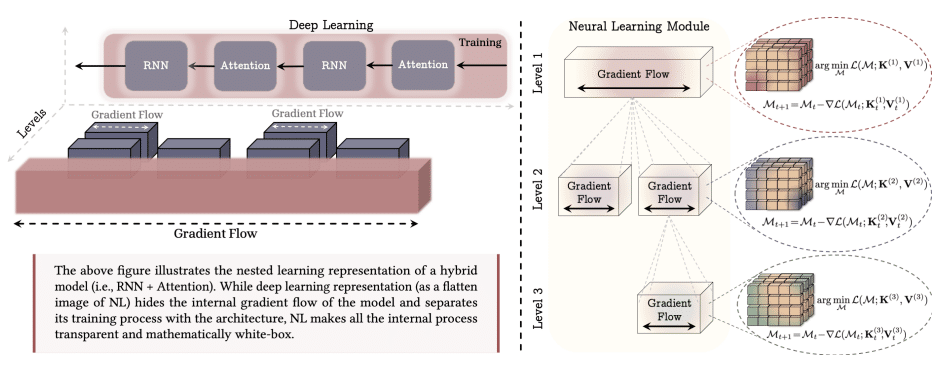
Google Research introduced Nested Learning, which casts training as nested optimization problems, aiming to unify model architecture and optimization to mitigate forgetting; a proof-of-concept self-modifying system named Hope demonstrated strong language modeling and reasoning performance with multi-timescale memory updates[7].
Evaluation, Benchmarks, and Open Challenges
Common retrospective metrics include average accuracy, backward transfer or forgetting, and forward transfer, each summarizing retention and plasticity across the task sequence[16][17].
Recent analyses caution that online accuracy can be unreliable for OCL, advocating for near-future accuracy that reduces spurious correlations while preserving relevance to immediate adaptation demands[19].
Surveys also highlight the need for fair comparisons that account for memory budgets, especially the storage of model parameters and exemplars, as well as stronger benchmarks in domains like healthcare and for long-horizon foundation model updates[9][3][2].
Across CL and OCL, research calls for algorithms designed under realistic compute constraints, theoretical advances beyond i.i.d. assumptions, and tighter integration with real-world data acquisition and novelty detection to support autonomous open-world learning[1][17].
Practical Guidance and Takeaways
- If privacy or storage prohibits replay, prefer strong regularization or architectural isolation; if permitted, replay remains a powerful baseline to establish reference performance[3][5].
- On-device and personalized scenarios benefit from lightweight updates, PEFT modules, and careful control of compute budgets to enable frequent refreshes without full retraining[1][4].
- For online agents, consider system-centric adaptation to improve success rates via inference-time orchestration when gradient-based updates are impractical[18].
- Use robust metrics beyond online accuracy, and report memory and compute alongside accuracy and forgetting to enable fair, reproducible comparisons[19][9].
Balancing Stability and Plasticity
An abstract illustration showing a balanced scale between retaining past knowledge and learning new information in a streaming environment.

Talks and Tutorials to Get Started
Search for recent conference tutorials and talks that explain continual learning foundations, class-incremental techniques, and online evaluation practices. These videos often include code walkthroughs and benchmark tips.
Conclusion
Continual learning enables models to adapt over time while preserving prior capabilities, with stable progress along replay, regularization, and architectural tracks, and a growing emphasis on online, real-time constraints[3][16]. In 2024–2025, class-incremental advances, system-centric online strategies, and practical paths for updating large foundation models stand out as key developments[8][18][4]. Looking ahead, improved evaluation, resource-aware methods, and integration with acquisition and alignment workflows will be critical for reliable deployment in dynamic environments[19][1][2].
Get more accurate answers with Super Pandi, upload files, personalized discovery feed, save searches and contribute to the PandiPedia.
Let's look at alternatives:
- Modify the query.
- Start a new thread.
- Remove sources (if manually added).