Legendary AI Papers
Highlights pivotal research papers in artificial intelligence that have had significant impacts on the field.
After the Astronef's encounter with the Martian fleet, Lord Redgrave retaliated against their hostile actions[1]. He rammed one Martian air-ship, causing it to break in two and plunge downwards through the clouds[1]. He also used an explosive shell, 'Rennickite,' to destroy another air-ship, leaving only a deep, red, jagged gash in the ground[1].
The Astronef then dropped onto the largest Martian air-ship, smashing it to fragments[1]. Following these attacks, the remaining Martian fleet scattered in all directions, sinking rapidly down through the clouds[1].
Let's look at alternatives:
- Modify the query.
- Start a new thread.
- Remove sources (if manually added).

Neurosymbolic AI approaches aim to combine statistical and analytical models, enabling robust, data-driven models for sub-symbolic parts while also facilitating explicit compositional modeling for overarching schemes. These systems strive to incorporate the strengths of neural networks and symbolic reasoning, thereby enhancing generalization capabilities and interpretability in AI systems.
Challenges in neurosymbolic AI include defining provable generalization properties and establishing effective learning structures that balance expressivity and computational efficiency. Recent research has explored richer formalisms to improve these models, focusing on compositionality and how generalizations can be effectively composed and applied across varying contexts[1].
Let's look at alternatives:
- Modify the query.
- Start a new thread.
- Remove sources (if manually added).
Get more accurate answers with Super Pandi, upload files, personalised discovery feed, save searches and contribute to the PandiPedia.
Let's look at alternatives:
- Modify the query.
- Start a new thread.
- Remove sources (if manually added).

Anthropic's Model Context Protocol (MCP) is an open standard designed to standardize how artificial intelligence (AI) models interact with various data sources, enabling secure, two-way communication between AI systems and these external resources. MCP acts like a universal connection point, facilitating integrations similar to how USB-C ports work for devices. This protocol allows for the integration of tools and automation of workflows, providing a framework for applications to easily connect to databases, APIs, and local data sources[1][2][3][5][6].
MCP follows a client-server architecture, where 'MCP Hosts' are applications like Claude Desktop or IDEs that want to access data, while 'MCP Servers' expose specific functionalities through the protocol. This structure allows for efficient data retrieval and interaction, enhancing the capabilities of large language models (LLMs) beyond their standalone functions[2][6].
Key benefits of MCP include a growing list of pre-built integrations, flexibility in switching LLM providers, and best practices for securing data. It simplifies the development process by eliminating the need for separate connectors for each data source, fostering a more manageable and scalable AI ecosystem[1][3][4].
Let's look at alternatives:
- Modify the query.
- Start a new thread.
- Remove sources (if manually added).
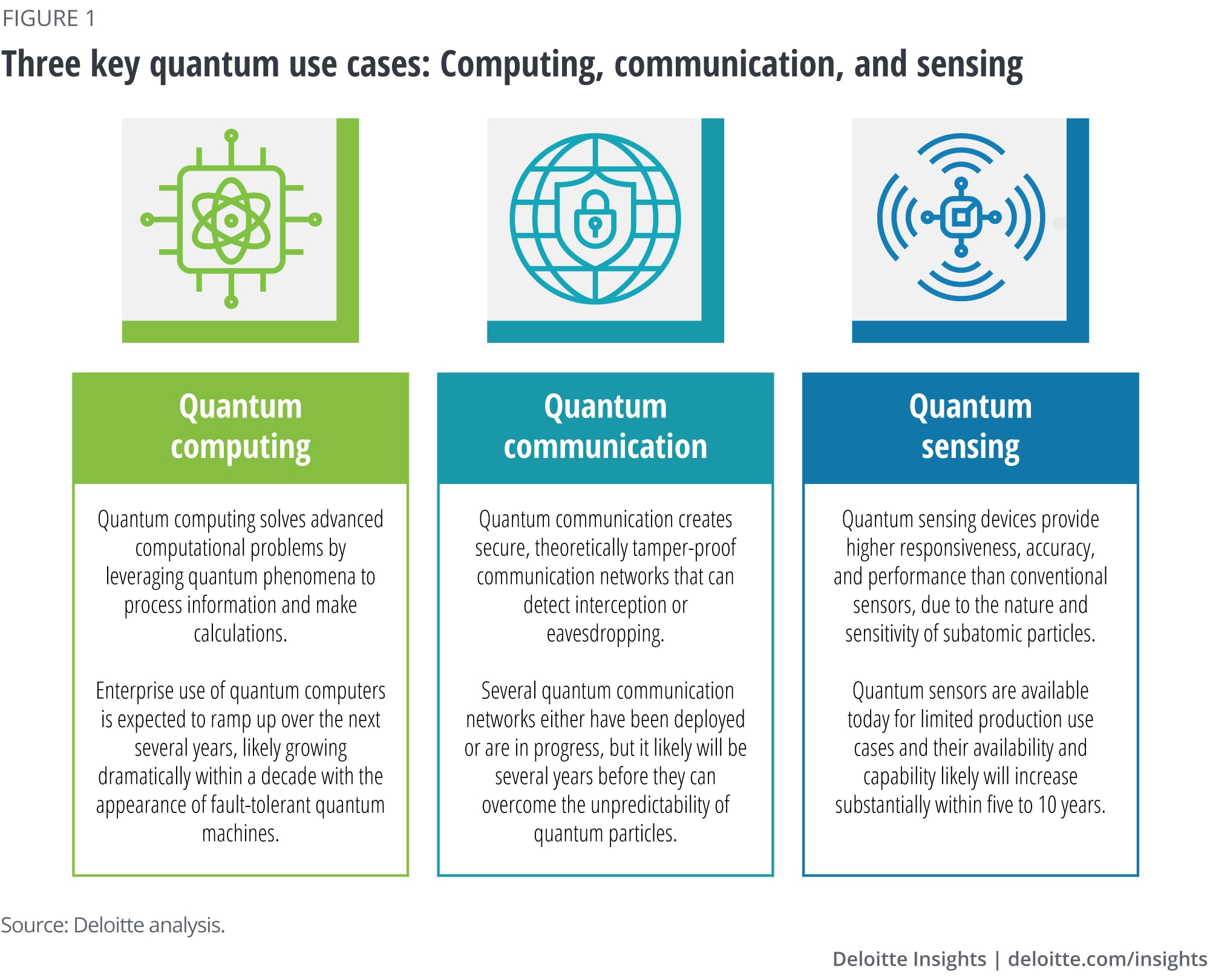
Navigating the Quantum Revolution: A C-Suite Imperative


Quantum computing is a revolutionary technology that leverages the principles of quantum mechanics to solve complex problems intractable for even the most powerful classical supercomputers[5]. For the boardroom, it is best understood as a new tool for managing immense complexity[5]. Unlike classical computers that use bits (either 0 or 1), quantum computers use 'qubits'[8]. A qubit can be a blend of both 0 and 1 simultaneously (superposition) and can be linked to other qubits (entanglement), allowing the machine to explore a vast number of possibilities at once[5]. This capability is not a distant dream; practical, scalable quantum computing is just a few years away and is essential for realizing the full potential of artificial intelligence[8]. The United Nations has declared 2025 the International Year of Quantum Science and Technology, signaling a global inflection point[5]. This is no longer a conversation for physicists; it has become a critical strategic discussion for the boardroom[5].
Myths and Realities of Quantum Commercialization

Navigating the quantum landscape requires separating persistent myths from the emerging commercial reality.
Myth 1: It's too early.
The reality is that the era of quantum commercialization has already begun[6]. Companies like Volkswagen and JPMorgan Chase are not waiting for a perfect quantum computer; they are engaging with what’s available to experiment with real-world optimizations and simulations today[6].
Myth 2: Only tech giants can succeed.
The quantum ecosystem is teeming with agile startups, many spun out of universities, that are not only competing with but also partnering with major tech companies[6]. For example, IonQ, founded by two professors, became the world's first publicly traded pure-play quantum computing company, demonstrating that academic origins can be turned into a multi-billion-dollar enterprise[6].
Myth 3: There's no market yet.
While the market is young, it is not nonexistent[6]. Early markets are forming now, driven by forward-thinking adopters in finance, pharmaceuticals, and logistics seeking a competitive edge[6]. Volkswagen's pilot project to optimize traffic flow in Lisbon using a quantum algorithm is a clear example of market interest[6].
Myth 4: We can just license the intellectual property (IP) later.
This passive approach is a risky myth. Early-stage quantum inventions are often too complex and nascent for a large company to license without the significant development and de-risking that a focused startup provides[6]. A startup acts as the necessary bridge, gathering inventors, raising capital, and building prototypes to prove the technology's value[6].
Defining Success: Understanding Quantum Advantage and Benchmarks


The ultimate goal is 'quantum advantage,' the ability to solve problems beyond the reach of classical computers[3]. However, a more practical milestone for businesses is 'quantum economic advantage,' which occurs when a problem can be solved more quickly with a quantum computer than with a comparably priced classical one[3]. An MIT framework likens this to a race between the 'Quantum Tortoise and the Classical Hare'[3]. Classical computers (the hare) are generally faster, but quantum computers (the tortoise) can use more efficient algorithms, taking a more direct path to the solution[3]. To measure progress, the field relies on benchmarks, defined as a set of tests designed to compare the performance of different computer systems[12]. A good benchmark must be relevant, reproducible, fair, verifiable, and usable[12]. Key metrics include:
- Quantum Volume (QV): Quantifies the largest square quantum circuit (equal width and depth) that a processor can successfully run[12].
- Q-Score: An application-focused metric measuring the maximum number of variables a quantum processor can handle in a standard optimization problem[12].
- Algorithmic Qubits (AQ): Measures the largest quantum circuit a processor can successfully run across six key algorithmic classes, moving beyond the square-circuit limitation of QV[12].
No single benchmark can capture all aspects of performance, so a suite of benchmarks is necessary for a comprehensive evaluation[12].
Early Applications: Quantum Computing Case Studies

Industry-led proof-of-concept studies are already demonstrating quantum computing's potential to solve practical challenges across various sectors[1]. These projects, facilitated by organizations like the UK's National Quantum Computing Centre (NQCC), provide a snapshot of current capabilities.
- Financial Services: A consortium explored quantum machine learning (QML) for credit card fraud detection[1]. Using quantum restricted boltzmann machines, the model showed competitive performance on a highly imbalanced dataset, achieving promising results with no false negatives and very few false positives[1].
- Healthcare: One project improved the classification of cancer cell types from liquid biopsies using a quantum support vector machine (QSVM)[1]. The quantum classifier successfully distinguished between cancer pairs, in some cases outperforming a classical deep neural network[1].
- Energy & Sustainability: To help advance climate goals, a project explored using quantum optimization to determine the optimal layout of turbines within an offshore wind farm to maximize energy production[1]. The problem was successfully implemented on photonic quantum hardware[1].
- Aerospace: A study assessed the feasibility of running Computational Fluid Dynamics (CFD) simulations on quantum hardware for aerodynamic design[1]. The results showed that measurement errors from current hardware had a negligible effect on simulation accuracy, preserving the performance advantage without sacrificing reliability[1].
Managing Quantum Risk: The Ticking Clock of Cybersecurity
’ with the subtext ’Foundation’, ’Quantum Key Distribution (QKD)’ with the subtext ’Secure exchange’, ’Quantum Random Number Generation (QRNG)’ with the subtext ’Entropy source’, ’Hybrid cryptography’ with the subtext ’Transitional")

The immense power of quantum computing presents an urgent and unavoidable threat to cybersecurity[5]. Leaders must prepare for the 'encryption cliff,' a point where quantum computers could break current encryption standards, making our digital world unsecure almost all at once[4]. This threat is amplified by the 'harvest now, decrypt later' strategy, where adversaries are capturing encrypted data today with the intent of breaking it once a powerful quantum computer is available[5]. The solution is Post-Quantum Cryptography (PQC), a new generation of encryption standards designed to be secure against attacks from both classical and quantum computers[5]. The U.S. National Institute of Standards and Technology (NIST) finalized its first set of PQC standards in August 2024[10]. A robust Quantum Risk Management (QRM) program begins with governance; boards must formally recognize quantum exposure as a critical strategic risk[2]. Key functions must be involved:
1. Security Architecture must create an inventory of where vulnerable algorithms are deployed to plan the transition[2].
2. Enterprise Risk Management (ERM) must integrate quantum risk into the enterprise risk register and define key risk indicators (KRIs) to measure exposure and progress[2].
3. Legal and Records Management must identify which records require long-term confidentiality and assess compliance obligations[2].
4. Product Engineering must design cryptographic agility into products, especially those with long service lives like IoT and medical devices, to allow for future updates[2].
A Practical Roadmap for Quantum Readiness

For C-suite leaders, the focus should not be on the technical details of hardware but on identifying 'quantum-ready' problems within the organization[5]. This problem-first approach grounds strategy in tangible business value[5]. Leaders should ask, 'Where are we currently relying on ‘good enough’ approximations instead of optimal solutions?'[5]. While the technology is emerging, the time for strategic planning is now. The global quantum computing market is projected to grow to USD 5.3 billion by 2029, and some companies already expect to invest over $15 million annually[10][3]. To prepare, leaders should:
- Leverage Cloud Platforms: The rise of Quantum-as-a-Service (QaaS) from providers like AWS, Azure, and IBM democratizes access, allowing companies to experiment and develop algorithms without massive capital expenditure[5].
- Build Talent: There is a significant quantum skills gap; McKinsey predicts that by 2025, fewer than half of quantum jobs will be filled[3]. Businesses must build a quantum-ready workforce by training existing employees, recruiting specialists, and collaborating with academic institutions[8].
- Develop a Roadmap: Proactively prepare for the transition to post-quantum cryptography. Consult technology partners to understand their roadmaps and identify whether legacy IT needs to be replaced sooner than planned, ensuring appropriate budget allocation[4].
Let's look at alternatives:
- Modify the query.
- Start a new thread.
- Remove sources (if manually added).
Deep neural networks have revolutionized many fields, particularly image recognition. One significant advancement in this domain is the introduction of Residual Networks (ResNets), which address challenges related to training deep architectures. This blog post breaks down the concepts from the research paper 'Deep Residual Learning for Image Recognition,' detailing the main ideas, findings, and implications for future work in the field.
The Challenge of Deep Neural Networks
As neural networks grow in depth, they become increasingly difficult to train due to several issues, including the degradation problem. This phenomenon occurs when adding more layers results in higher training error, counterintuitively leading to worse performance on benchmarks. The authors hypothesize that instead of learning to approximate the desired underlying function directly, it's easier to learn a residual mapping, which represents the difference between the desired output and the initial input[1].
To address this, the authors propose a deep residual learning framework. Instead of hoping that a few stacked layers can model a complex function directly, ResNets reformulate the layers to learn residual functions relative to the layer inputs, thereby promoting easier optimization and improved accuracy with increased network depth.
The Structure of Residual Networks
Residual Networks incorporate shortcut connections that bypass one or more layers. This allows the network to learn residual functions, effectively simplifying the learning task. The formulation includes an identity mapping, making it easier for the optimization algorithms to incorporate the original input, thereby accelerating convergence[1].
The backbone of a ResNet includes components like convolutional layers and batch normalization (BN), which work together to stabilize and accelerate training. The authors demonstrate that their ResNet architecture achieves a notable reduction in error rates on standard datasets, achieving significant competitive results compared to existing methods.
Key Findings and Experiments
 of single-model results on the ImageNet validation set (except † reported on the test set).")
In their experiments, the authors evaluated ResNets across multiple benchmarks, including ImageNet, CIFAR-10, and COCO detection tasks. They found that deeper networks (up to 152 layers) consistently outperform shallower networks like VGG, which uses up to 19 layers. For instance, a ResNet with 152 layers achieved a top-5 error rate of 3.57%, compared to 7.3% for the VGG-16 model[1].
Moreover, the paper presents compelling evidence that residual learning allows for deeper architectures without suffering from the degradation problem exhibited by plain networks. This is illustrated through training procedures that highlight the lower training errors and improved validation performance for deeper ResNets[1].
Architectural Innovations
![Table 6. Classification error on the CIFAR-10 test set. All methods are with data augmentation. For ResNet-110, we run it 5 times and show “best (mean±std)” as in [43].](https://askpandipro.s3.amazonaws.com/users/48/documents/142/tables/4.png?AWSAccessKeyId=AKIAQT4QH3CHNPX5WHX7&Signature=wBNY40b1sZPQlHnSkOQVsbq36Go%3D&Expires=1775896074?AWSAccessKeyId=AKIAQT4QH3CHNPX5WHX7&Signature=Sej7LNrzJ50FhgU7%2B%2BeoQGisNno%3D&Expires=1775522627?AWSAccessKeyId=AKIAQT4QH3CHNPX5WHX7&Signature=MfERlg21QxwBlMvOThWg2BxtFJ8%3D&Expires=1774725842 "Table 6. Classification error on the CIFAR-10 test set. All methods are with data augmentation. For ResNet-110, we run it 5 times and show “best (mean±std)” as in [43].")
The design of ResNets is grounded in practical considerations. For instance, the authors employed a bottleneck architecture in very deep ResNets. This involves using short, narrow layers (commonly 1x1 convolutions) to reduce dimensionality before the main processing occurs, thereby maintaining complexity while allowing for deeper networks. They tested various configurations, confirming that the addition of these bottleneck layers does not significantly increase the number of parameters, but yields much better performance[1].
Implications for Future Research
The insights gained from deep residual learning have profound implications for future research in neural network architecture and optimization. One of the significant takeaways from the study is that while deeper networks can achieve remarkable accuracy, they also necessitate careful design to mitigate issues related to overfitting and saturation of activations.
The authors also highlight the iterative nature of developing effective network architectures, noting that future developments might involve exploring multi-scale training strategies or advanced techniques for optimizing residual connections and layer compositions.
Conclusion
Deep residual learning introduces a transformative approach to training deep neural networks, particularly for image recognition tasks. By reformulating how layers interact and utilizing residual functions, researchers and practitioners can develop more powerful models that maintain high accuracy even as complexity increases. The advancements presented in this paper set a robust foundation for continuing innovations within the realm of neural networks, promising significant enhancements in various applications beyond image recognition[1].
With these developments, the field is well-positioned to tackle even more complex challenges in visual recognition and other domains where deep learning frameworks can be applied.
Let's look at alternatives:
- Modify the query.
- Start a new thread.
- Remove sources (if manually added).
Get more accurate answers with Super Pandi, upload files, personalised discovery feed, save searches and contribute to the PandiPedia.
Let's look at alternatives:
- Modify the query.
- Start a new thread.
- Remove sources (if manually added).

Instance-based AI methods, referred to as lazy learning methods, are non-parametric techniques that focus on local inference rather than global modeling. These methods derive their predictions based on previously encountered similar cases, operating as needed. An example of this approach is the nearest-neighbor methods, which are flexible and can adjust their complexity according to the available data. They also have the capability for universal approximation, meaning they can handle various tasks as long as suitable data structures are available. Instance-based methods rely on memorizing single instances, which helps them identify out-of-sample instances based on similarity to experienced data, and they can effectively deal with catastrophic forgetting in continual learning scenarios by retaining relevant prior data points. This principle also enables them to respond to distributional changes effectively, although the choice of representation greatly influences their generalization ability【1】.
Let's look at alternatives:
- Modify the query.
- Start a new thread.
- Remove sources (if manually added).
Let's look at alternatives:
- Modify the query.
- Start a new thread.
- Remove sources (if manually added).
The gpt-oss models utilize the o200k_harmony tokenizer, which is a Byte Pair Encoding (BPE) tokenizer. This tokenizer extends the o200k tokenizer used for other OpenAI models, such as GPT-4o and OpenAI o4-mini, and includes tokens specifically designed for the harmony chat format. The total number of tokens in this tokenizer is 201,088[1].
This tokenizer plays a crucial role in the models' training and processing capabilities, enabling effective communication in their agentic workflows and enhancing their instruction-following abilities[1].
Let's look at alternatives:
- Modify the query.
- Start a new thread.
- Remove sources (if manually added).