Federated Learning for Personalized Healthcare: Architecture, Differential Privacy, and Wearable Applications
Introduction
Federated learning (FL) has emerged as a promising approach to enable personalized healthcare without centralizing sensitive data. By distributing the training process over multiple local sites, FL preserves patient privacy while aggregating insights from diverse and often siloed data sources[1]. This report presents an overview of the FL architecture, details on differential privacy methods used in health and wearable ecosystems, application cases, and performance benchmarks along with current limitations.
Federated Learning Architecture

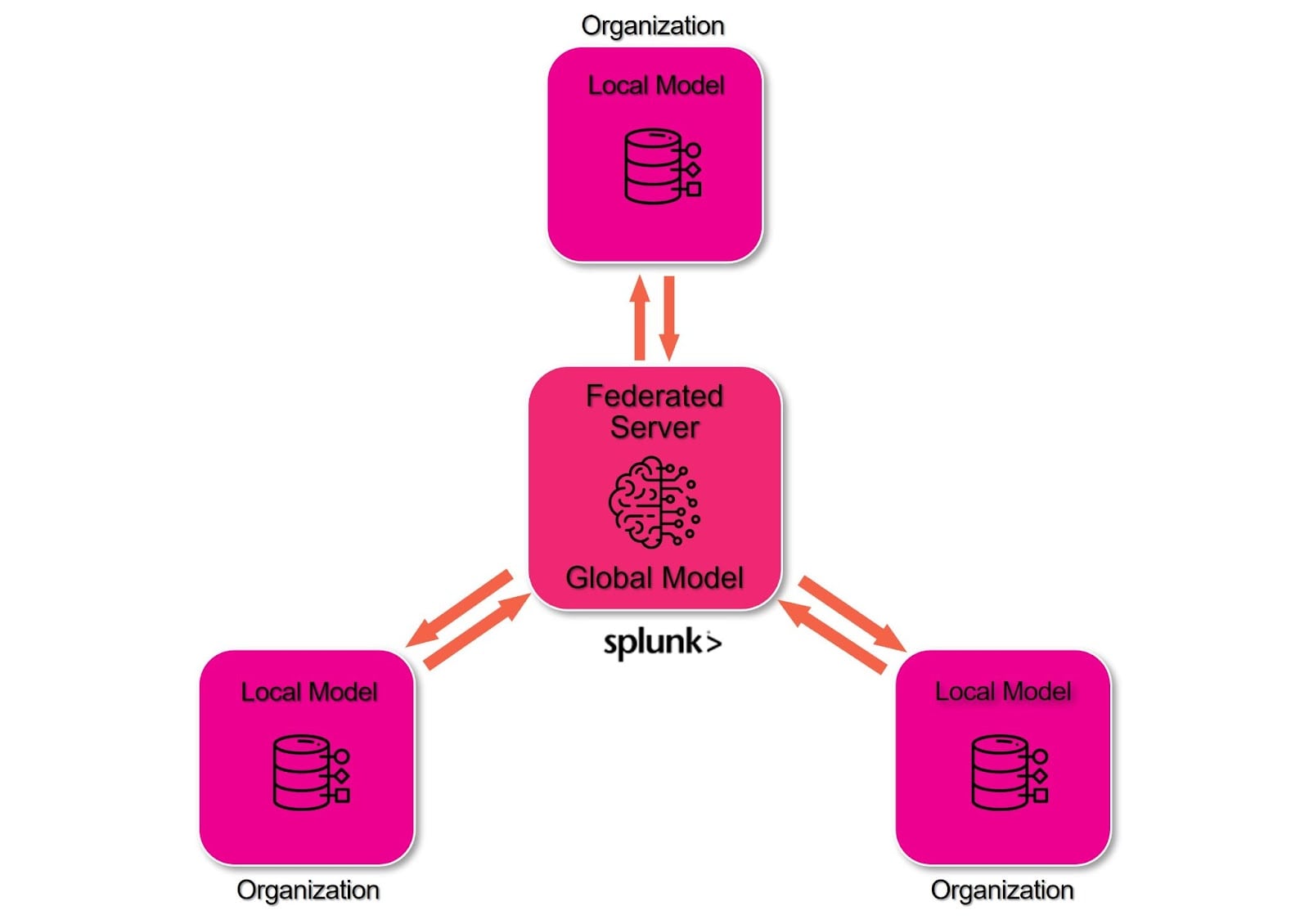
In a typical FL architecture, a centralized server initializes a global model and broadcasts its parameters to participating devices or institutions. Each client then uses its local data to train a model that shares the same architecture as the global model, and only the updated parameters are sent back to the central server for aggregation[1]. This approach ensures that raw data remain on-site, thus mitigating privacy risks associated with traditional centralized machine learning. In addition, the concept of data partitioning is fundamental, where sites may share the same feature space (horizontal FL) or have complementary features (vertical FL), which is particularly relevant in collaborative healthcare environments[1]. Organizations such as those highlighted in industry applications are leveraging FL to aggregate models without compromising data ownership, thus bridging the gap between medical research and advanced analytics[5].
Differential Privacy Techniques in Healthcare

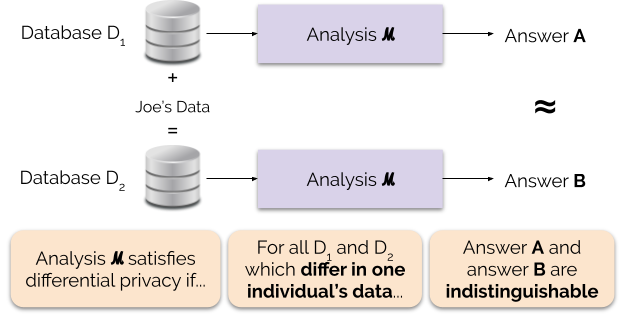
Differential privacy (DP) is increasingly incorporated into FL frameworks to strengthen privacy guarantees during model training. In local differential privacy, noise is added to data on the user device before transmission, ensuring that even model updates do not reveal sensitive details[2]. For instance, mechanisms that combine the Laplace mechanism with randomized response methods are used to perturb data points in real-time, especially for streaming health data from wearable devices[2]. Additionally, systematic reviews of wearable health data publishing under DP demonstrate that careful calibration of the privacy budget is crucial; a smaller privacy budget offers stronger privacy but may decrease data usability, whereas a larger budget recovers some utility at the potential cost of privacy[7].
Application Cases in Wearable Ecosystems


Wearable devices continuously collect various physiological data such as heart rate, blood pressure, and activity levels that are essential for remote health monitoring and personalized medical care. Federated learning in wearable ecosystems facilitates the joint training of models on these sensitive data streams while ensuring that individual data remain on the device[2]. Industry examples illustrate that collaborative FL setups not only protect privacy but also enable insights from diverse sources – for example, consortiums can pool chemical libraries or clinical trial data without exchanging raw information[5]. Such approaches demonstrate the potential to improve diagnostics, treatment personalization, and even drug discovery by leveraging previously inaccessible datasets.
Performance Benchmarks


Performance evaluation of federated learning models has been performed on several benchmark datasets. In controlled experiments using simple datasets such as MNIST, FL frameworks have achieved global model accuracies of around 82% under IID data conditions, whereas non-IID data distributions caused steep drops in performance, with mean accuracies as low as 17% in some scenarios[4]. Furthermore, the introduction of differential privacy techniques involves a trade-off between accuracy and privacy; increasing the privacy budget tends to improve model accuracy, yet the addition of noise can also delay convergence or reduce performance when excessive[4]. Simulations also underscore that computational resource disparities among devices may lead to slower convergence, with straggler effects notably impacting training speed despite similar final accuracy levels[4].
Limitations and Future Directions

Despite its strong potential, federated learning faces several limitations that must be addressed for broader clinical adoption. One notable challenge is the risk of privacy leakage during the sharing of model updates; even though raw data remain local, reconstruction or membership inference attacks remain possible if adversaries analyze the transmitted weights[1]. Communication overhead is another critical limitation because as the number of participating devices grows, the volume of data exchanged increases significantly, which can slow down model convergence and require significant network resources[6]. Additionally, device heterogeneity and non-uniform data distributions challenge the fairness and stability of the global model, as evidenced by stark performance differences between IID and non-IID settings[4]. Future research should focus on improved client selection, adaptive aggregation strategies, and sophisticated privacy-preserving algorithms to balance privacy with model utility. The integration of techniques such as homomorphic encryption, secure aggregation, and federated meta-learning is also anticipated to enhance both the security and scalability of FL in healthcare[7].
Get more accurate answers with Super Pandi, upload files, personalized discovery feed, save searches and contribute to the PandiPedia.
Let's look at alternatives:
- Modify the query.
- Start a new thread.
- Remove sources (if manually added).