In Elasticsearch, when using rank vectors, can the embedded vectors be of multiple variable size? Point is that if the multi vectors are of fixed size, then some information might be lost.
Research Question and Short Answer
Objective: In Elasticsearch, when using rank vectors, can the embedded vectors be of multiple variable size? If the vectors are fixed size, might information be lost? Short answer: No. Elasticsearch's rankvector field requires that vectors in the field all have the same number of dimensions and a consistent element type, so you cannot store variable-length vectors in a single rankvector field[2][1].

How rank_vector Works and Its Constraints
Elasticsearch's rank_vector field type is designed for late‑interaction dense vector scoring and is typically used for second‑order re‑ranking of candidate documents based on similarity between a query vector and vectors stored in the field[1].
Critically, rankvector imposes uniformity: all vectors stored in a given rankvector field must share the same number of dimensions and the same element type[2].
The field can be used with similarity functions intended for late interaction scoring, including maxSim and asymmetric variants like maxSimDotProduct for comparing floating‑point query vectors against bit vectors, but the dimensionality must still match across the vectors being compared[3].
In practice, rank_vector fields are accessed during re‑ranking, letting you refine ordering of a small set of candidates retrieved by an initial query phase while keeping vector scoring consistent and efficient[1].
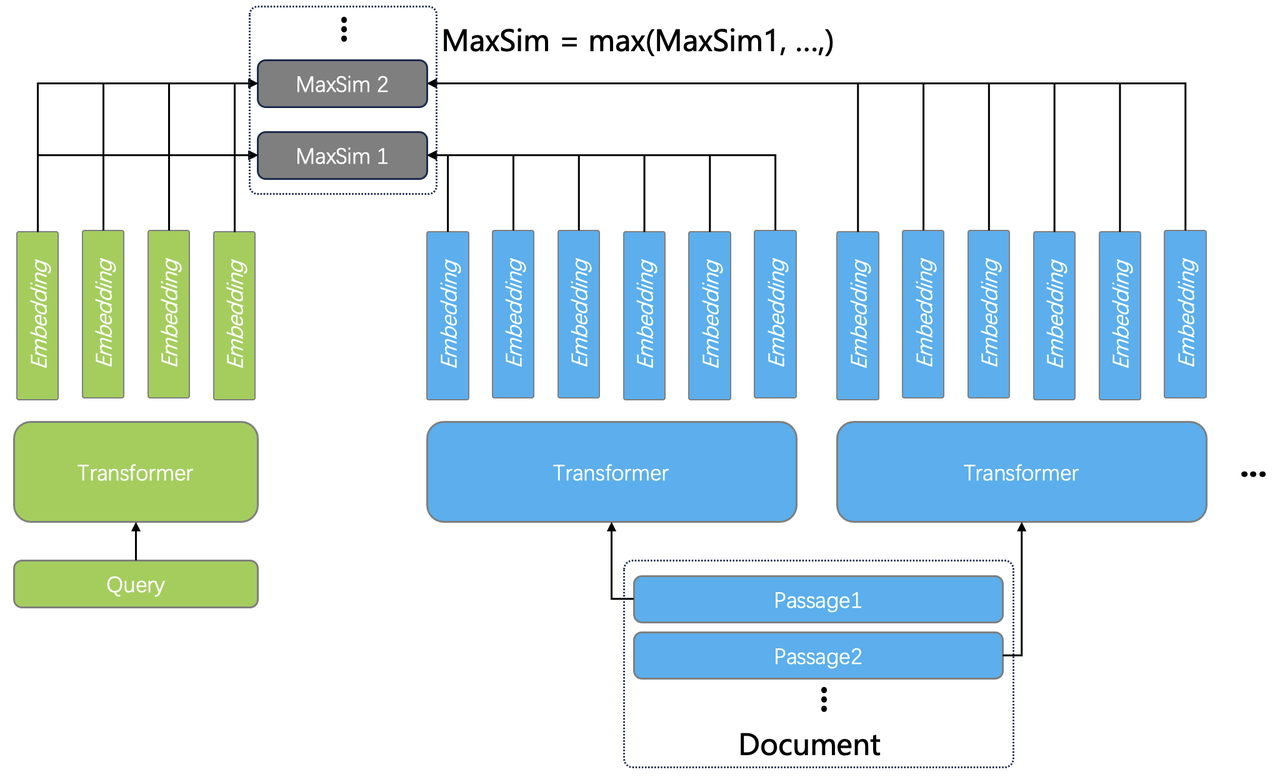
Dense Vector Fields Also Require Fixed-Length Embeddings
Elasticsearch's dense_vector field type stores an array of numeric values with a fixed dimensionality, which must be consistent for every document stored in that field[11].
When defining a mapping, you specify the number of dimensions for the dense_vector; if not explicitly specified, Elasticsearch infers the dimensionality from the first vector indexed and enforces the same length for all subsequent vectors in that field[8].
This fixed size allows Elasticsearch to compute similarity metrics (for example, cosine similarity or Euclidean distance) and to support efficient k‑nearest neighbor search by comparing corresponding positions across vectors[11][9].

Implications for Variable-Length Embeddings and What You Can Do
Elasticsearch does not support variable‑length embeddings within a single vector field: both rankvector and densevector require fixed dimensionality across all vectors stored in the same field[1][11].
- Standardize embeddings per field: choose a dimensionality and pad or truncate vectors from your model to that size before indexing. This is the most common approach in production systems.
- Use separate fields for different sizes: if you need to support multiple embedding dimensionalities, create multiple vector fields in the same index (for example, titlevec384 and titlevec768) and decide at query time which field to use.
- Use separate indices per model: if operationally simpler, create distinct indices for each embedding size and query the ones that match your query embedding.
- Late interaction and asymmetric scoring: if your use case benefits from late‑interaction scoring or from comparing float query vectors to compact bit vectors, rank_vector supports these scoring modes, provided the dimensions match across vectors you compare[3].
- Re‑rank a candidate set: retrieve candidates with classical search first, then re‑rank with rank_vector similarity to stay efficient while applying vector scoring consistently[1].
Note that if you worry about information loss from truncation or padding, you can mitigate it by selecting an embedding model with a dimension that balances fidelity and cost, and by using multiple fields or indices to preserve different representations for different content types. These are engineering trade‑offs rather than features of Elasticsearch itself.

Dimension Limits, Indexing, and Practical Constraints
Dense_vector fields have dimensionality constraints that depend on whether the field is indexed for kNN; community and issue tracker discussions note a typical upper bound of 1024 dimensions for indexed vectors, with higher limits (often up to 2048) for unindexed vectors[6][5].
If you try to index a vector whose length exceeds the configured or allowed dimensionality, Elasticsearch will reject the document and return an error, making it important to fix and enforce shape at ingestion time[7].
These limits reinforce why Elasticsearch enforces fixed vector lengths per field: consistent dimensionality is required both for correctness in similarity scoring and for performance characteristics of the underlying vector indices[11].
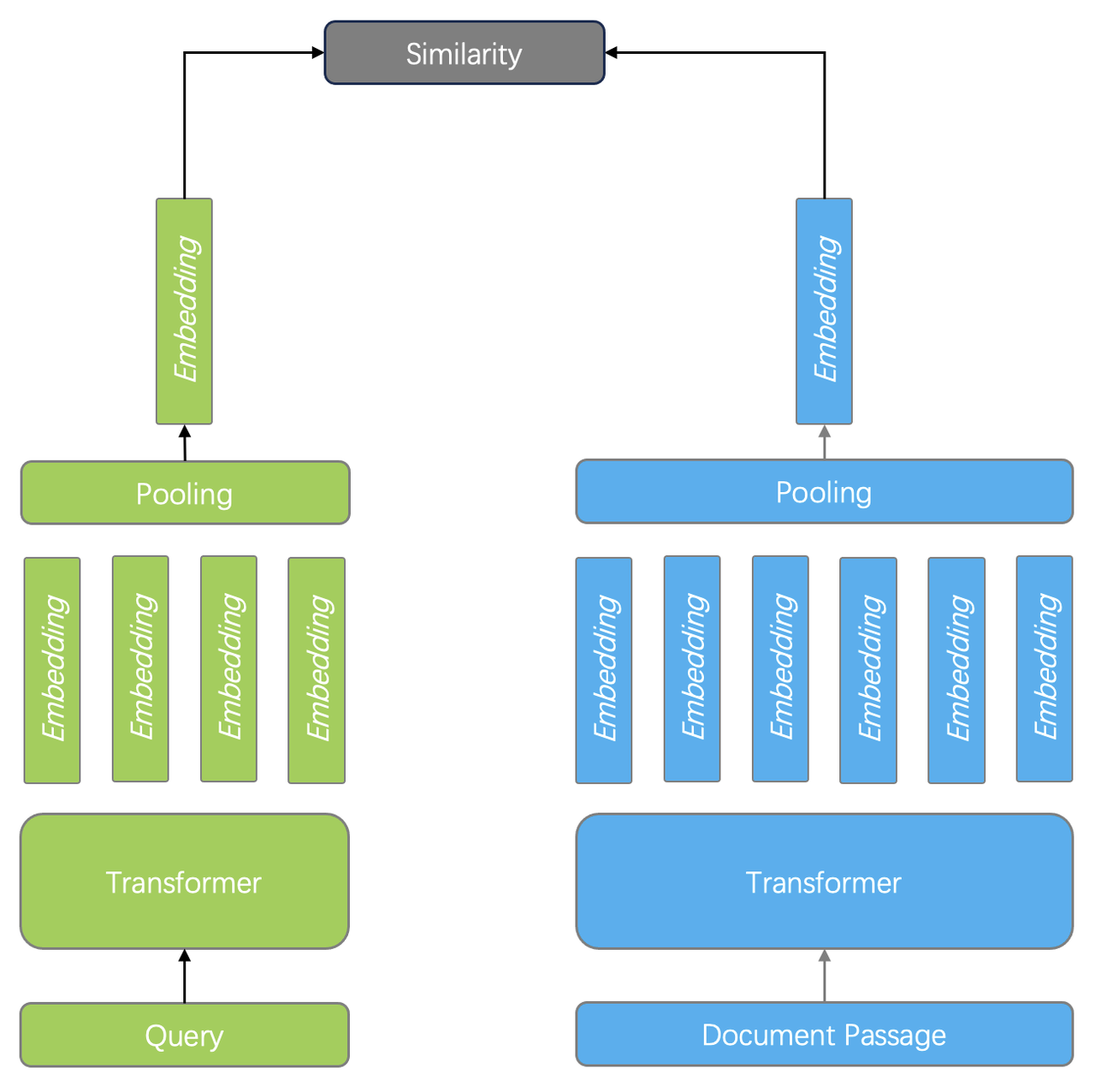
")
Recommendations
- If you use rank_vector, decide a single vector width per field and keep it constant across all documents[2].
- For mixed‑dimension needs, create additional fields or indices to house different embedding sizes and query the appropriate one for each request.
- For efficiency, retrieve with standard text queries and re‑rank with rank_vector similarity, which is the pattern Elastic documents for late‑interaction use cases[1].
- When using dense_vector kNN, keep dimension limits in mind and verify that your chosen embedding size stays within Elasticsearch's supported bounds for your version and configuration[6][11].

Conclusion
Elasticsearch does not support variable‑length embeddings within a single rankvector or densevector field; each such field has a fixed dimensionality that all stored vectors must share[2][11].
To accommodate multiple sizes without losing information, adopt a schema that uses multiple fields or indices and apply re‑ranking with rankvector or kNN with densevector as appropriate to your workflow[1].

Get more accurate answers with Super Pandi, upload files, personalized discovery feed, save searches and contribute to the PandiPedia.
Let's look at alternatives:
- Modify the query.
- Start a new thread.
- Remove sources (if manually added).