Limitations in Reasoning Models When Provided with Explicit Algorithms
Overview

Recent studies have indicated that even when a complete algorithm is provided in the prompt, reasoning models fail to execute it accurately. This phenomenon highlights a deeper issue: these models have substantial limitations in both verifying the correctness of each step and following logical sequences as prescribed. The models’ inability to benefit from explicit algorithmic guidance exposes critical weaknesses in their reasoning capabilities. The text from the source explains that despite being given a recursive algorithm for the Tower of Hanoi, the model’s performance does not improve, and the failure point remains unchanged[1].
Inadequate Execution of Prescribed Algorithms


A key observation made in the study is that providing the exact solution algorithm does not lead to improved performance. For instance, in the Tower of Hanoi experiments, even when the recursive method was explicitly provided in the prompt, the failure in executing the solution occurred at nearly the same point as when the algorithm was not given. The source text states: "even when we provide the algorithm in the prompt—so that the model only needs to execute the prescribed steps—performance does not improve, and the observed collapse still occurs at roughly the same point." This clearly indicates that these models face difficulties with consistent logical step execution, regardless of whether they must discover the algorithm independently or merely follow provided instructions[1].
Limitations in Verification and Consistency
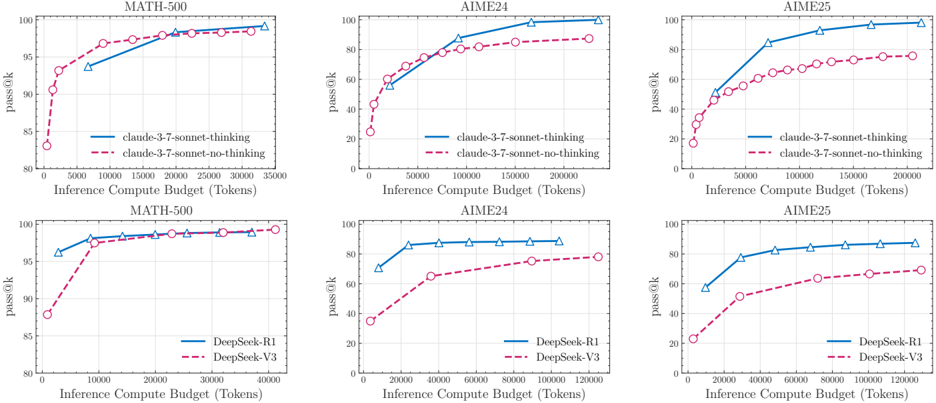
The inability to effectively follow and verify algorithmic steps is central to the failure of reasoning models when explicit algorithms are provided. The source material emphasizes that "finding and devising a solution should require substantially more computation (e.g., for search and verification) than merely executing a given algorithm." This suggests that the models are not only challenged by the process of devising novel solutions but also by the execution of known and provided methods. The internal process of verifying the correctness of every step appears to be insufficient. Due to these verification limitations, the models tend to collapse in performance as soon as the complexity increases, leading to an early error in the sequence of operations. This inconsistency in reasoning and verification means that even the simplest hints in the form of explicit algorithms do not translate into better performance during problem solving[1].
Underlying Computational and Logical Barriers


The experiments described in the text reveal that the reasoning models have inherent computational and logical scaling limits. As the complexity of the tasks increases, the models initially invest more tokens to reason through the problem; however, near a critical complexity threshold, their reasoning effort decreases despite the problems becoming harder. This counterintuitive behavior underscores a primary limitation: a shortfall in the capacity to dynamically adjust their verification routines as problem complexity increases. Even with the algorithm provided, the expected benefit of reduced search space and simpler execution conditions is not realized because these models still fail to properly track state transitions and maintain logical consistency across multiple steps. In essence, the failure is not solely due to the inability to find a solution, but also due to an intrinsic mismanagement of the execution process when following a set of explicit directives[1].
Implications for Future Research


The failure of reasoning models to harness the benefits of a provided algorithm calls for further investigation into their symbolic manipulation and logical verification capabilities. The observed limitations suggest that current training methods, although effective in generating chain-of-thoughts, are insufficient for developing robust, algorithmic reasoning skills that are crucial for precise and error-free problem solving. This shortfall indicates that future models may need enhanced mechanisms for exact computation and improved frameworks that focus on consistency in step-by-step logical execution. Researchers are thereby encouraged to explore hybrid approaches that combine both pattern recognition and strict algorithmic verification to overcome these fundamental barriers[1].
Conclusion

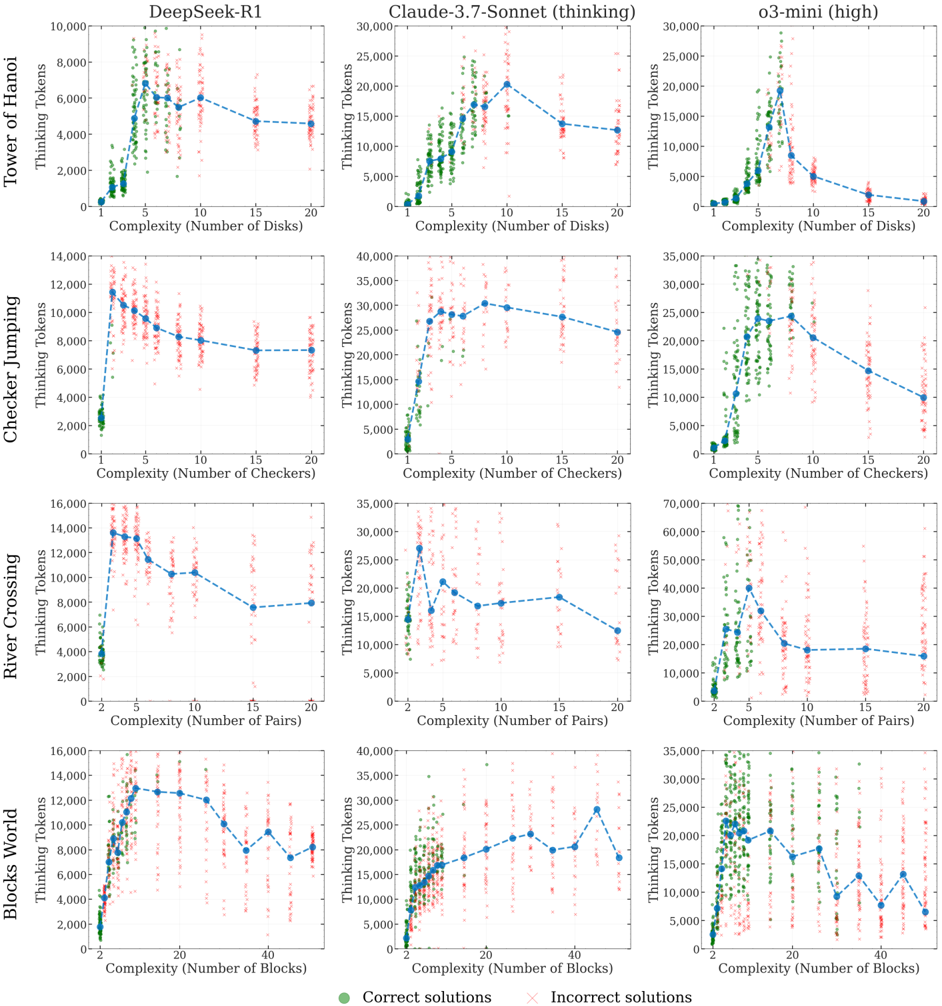
In summary, reasoning models fail to benefit from explicitly provided algorithms due to their inherent limitations in step verification and logical consistency. Despite improved chain-of-thought mechanisms, the failure to translate an algorithm into a reliable sequence of actions highlights a major challenge in artificial intelligence research. The verification process remains inadequate, and models exhibit similar performance collapse regardless of whether the algorithm is self-generated or supplied. This points to a need for future work focused on enhancing the symbolic and verification capabilities of reasoning models to ensure that explicit guidance can be effectively executed in practice[1].
Get more accurate answers with Super Pandi, upload files, personalized discovery feed, save searches and contribute to the PandiPedia.
Let's look at alternatives:
- Modify the query.
- Start a new thread.
- Remove sources (if manually added).