What is Quantisation in ML?
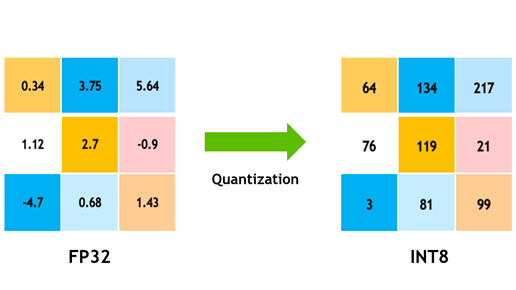
Quantization in Machine Learning[1] (ML) is the process of reducing the precision of data to smaller formats, such as converting from floating point 32 bits[1] to integer 8 bits. This process aims to reduce memory space and computational complexity in neural networks, making them faster and requiring less storage space. It involves techniques such as range mapping, calibration, and post-training quantization. The goal is to maintain accuracy within 1% of the original accuracy while achieving a speedup of at least 2X[1] during calculations. Quantization affects deep learning networks[2] by reducing memory and power consumption[2], and the process is aimed at achieving acceptable accuracy while deploying the quantized network to embedded devices. Additionally, there are different approaches for quantizing a model, such as dynamic and static quantization, as well as quantization-aware training. It is crucial for maintaining accuracy and improving the performance of ML models, especially for deployment on edge devices with strict power and compute requirements[6].
Get more accurate answers with Super Pandi, upload files, personalized discovery feed, save searches and contribute to the PandiPedia.
Let's look at alternatives:
- Modify the query.
- Start a new thread.
- Remove sources (if manually added).